肖雯娟 西北民族大学电气工程学院 730000
【文章摘要】
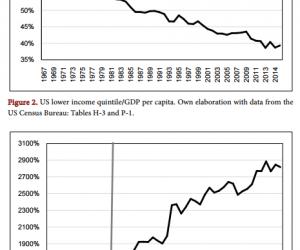
本文设计了一种基于MATLAB 的图形用户界面系统,通过对孤立词语音信号进行预处理,使用梅尔倒谱系数参数特征提取,最后运用动态时间调整(DTW)算法,实现了对0-9 十个孤立数字的识别,识别率正确率为100%,为复杂语音识别研究奠定了理论基础。
【关键词】
语音识别,孤立词,梅尔倒谱系数,动态时间调整
0 引言
语音识别( Speech Recognition) 是机器通过识别和理解的过程把人类的语音信号转变为相应的文本或命令的技术。其根本目的是研究出一种能直接或间接接收人的语音并能理解人的意图, 具有听觉功能的机器。
本文在MATLAB 环境中构建了孤立词语音识别GUI 平台,经过预处理之后选择了Mel 频率倒谱系数MFCC(Mel Frequency Cepstrum Coefficient)特征参数提取方法和动态时间调整算法DTW (Dynamic Time Warping) 等来对指定目录的孤立词进行识别。
1 孤立词语音系统的基本结构
孤立词语音识别以特定的不连续的词语作为处理单元。语音识别系统的基本组成一般可以分为采集模块、处理模块及识别模块三个模块。如图1 所示为语音识别系统结构框图:
2 原理与设计
2.1 预处理与特征提取
语音信号是一种十分特别的的非平稳信号,录制过程中很容易受到各种噪音的影响,所以语音信号要经过一系列的预处理过程后才可进行特征参数提取等工作。识别开始后,语音信号经过类似的通道生成模板,用相同的方法计算测试模板的各种特征参数后,将其与模板库模板的特征参数进行匹配,配分数最高的参考模板作为识别结果。预处理过程通常包括预加重、加窗、分帧、端点检测等部分。加窗分帧是将语音信号分段处理, 这时的信号连续并保持了一定的重叠率;而端点检测是通过一定处理, 将没有意义的信号去除,进而确定出有用信号命令的起始点和终止点,从而减少语音匹配识别的MATLAB 计算量,同时也可提高系统识别率。图2 为语音信号处理过程中预处理及特征参数提取的步骤。
计算过程:
①预加重: 为了便于信号的传输或记录,而对某些频谱分量的幅值相对于其他分量的幅值预先有意予以增强的措施。语音识别中最有用的是高频部分,而对于频谱来说,通常是频率越高幅值越低。因此,必须对语音高频加重处理。一般是将信号通过一个一阶高通滤波器,它不仅能滤除低频提升高频,还能很好的抑制50~60Hz 的工频干扰。在端点检测之前进行预加重过程不仅抑制了随机噪声、消除了直流漂移,还可以起到提升清音部分能量的效果。
(1)
②加汉明窗: 语音信号具有短时平稳特性,在较短的时间内可以忽略语音信号的时变特性,基于此特征,可以将截取的一段语音信号来进行分帧。分帧的具体过程就是将窗函数加入语音信号来实现,即,其中为加窗前的语音信号, 为窗函数, 为加窗后的信号,此处使用汉明窗。
(2)
③ FFT
(3)
④对频谱进行三角滤波: 程序采用归一化mel 滤波器组系数
⑤计算每个滤波器的输出能量
(4)
⑥离散余弦变换(DCT) 得到MFCC
(5)
通常协方差矩阵一般取对角阵,三角滤波器组的对数能量输出之间存在着很大的相关,采用 DCT 这种正交变换可以去除参数之间的相关性,从而使后端识别模型采用对角阵具有更高的识别率。
⑦归一化倒谱提升
(6)
⑧计算差分系数并合并MFCC 参数和一阶差分MFCC 参数将其作为一个整体,让参数更完备。
2.2 动态时间规整法
鉴于动态时间规整(DTW) 算法在训练中不需要额外的计算,故在识别部分采用DTW 算法。
在设计程序时,首先申请两个n×m 的矩阵D 和d,分别为累积距离和帧匹配距离。这里n 和m 为测试模板与参考模板的帧数。然后通过一个循环计算两个模板的帧匹配距离距阵d。接下来进行动态规划,为每个格点(i,j)都计算其三个可能的前续格点的累积距离D1、D2 和D3。考虑到边界问题,有些前续格点可能不存在,因此要加入一些判断条件。最后利用最小值函数min,找到三个前续格点的累积距离的最小值作为累积距离,与当前帧的匹配距离d(i,j)相加,作为当前格点的累积距离。该计算过程一直达到格点(n,m),并将D(n,m)输出,作为模板匹配的结果。
3 仿真分析
为了验证系统设计的正确性,在MATLAB 中进行了仿真实验,在无过多噪音的室内进行了录音,搭建了基于动态时间调整(DTW)的孤立词语音识别系
图3 用户界面
图1 语音识别系统结构框图
图2 预处理及特征参数提步骤008
电子科技
Electronics Technology
电子制作
存器是16 位的,最大只能计数到65535,这就限定了比较/ 捕获的最小输入频率, 因此上述方法已经不能准确测量方波的频率。要想在频率较小时测量方波频率,我们可以对定时器时钟频率做分频处理, 将定时器时钟频率设置为1MHz,就可以测量频率较小的输入脉冲信号,当然也可以采用单片机的计数模式,将stm32 单片机的通用定时器设定为计数模式,测量在1S 内输入的脉冲个数即为输入信号的频率。本设计中为了测量较小频率的信号,我们对定时器时钟频率进行了分频处理, 最终测出的最小频率可达10Hz。
3 结论
本次所设计频率计的测量范围可达10Hz~1MHz,测量精度小于0.1%,可对幅值在0.05V~5V 之间的周期信号进行测量。由于STM32 单片机是一款高性能、低成本、低功耗的单片机,目前在许多有关单片机设计的问题中,得到了广泛的应用,本设计采用stm32 单片机作为主控芯片,在使用较少外围器件的情况下,主要靠软件控制,实现高精度频率的测量。
【参考文献】
[1] 田磊. 基于 AT
[2] 钱进. 基于AT
[3] 马忠梅, 籍顺心. 单片机的C 语言程序设计[M] 北京: 北京航空航天大学出版社,2003
[ 4 ] S T M 3
统,通过预处理,特征提取,模式识别等模块分别处理,训练顺利完成了对训练库内0-9 所有语音文件的语音识别。
3.1 用户界面
MATLAB 提供了图形用户界面开发环境,这使得界面设计在可视化状态进行,设计过程变得简单直观,设计中利用GUI 开发界面建立了可识别0-9 汉语数字的MATLAB 仿真语音识别系统。该系统既操作方便,又界面友好,使用者可在不需要了解具体的程序代码和面对冗长的代码的情况下就可以方便的操作。图3 所示为用户界面。
3.2 仿真实验结果
选择“4”作为孤立词语音识别文件进行训练,经过预处理,特征提取,模板训练,模式识别等过程达到了良好的识别效果,图4 为仿真实验结果。
4 结论
本文介绍了语音识别开发的过程, 分析了前端预处理、端点检测以及特征参数提取的原理和算法,在模式匹配方面采用动态时间规整算法,并用MATLAB 中用图形用户界面进行演示,仿真表明该算法能有效进行孤立词语音识别,并能有效减小噪声所带来的训练模型与测试语音之间的失配。
【参考文献】
[1] 王明奇. 基于HMM 的孤立词语音识别系统的研究[D]. 中南大学, 2007.
[2] 付丽辉. 语音识别关键性技术的MATLAB 仿真实现[J]. 仪器仪表用户, 2010
[3] 王文延. 匹配追踪时频分解算法的端点检测方法[J]. 声学技术, 2007
[4] 张培玲, 成凌飞. 基于MATLAB 的汉语数字语音识别系统[J]. 机械管理开发, 2011
图4(a)原始波形、放大结束出波形图 图4(b)短时过零率、短时能量
图4(c) 设置门限 图4(d)端点检测、滤波
图4(e) 显示功率谱 图4(f) 显示结果为“4”
》 接001 页009








论文发表 是一个专门从事期刊推广、论文发表、论文发表辅导的机构。融合收集数百家期刊杂志社征稿评职称,发表论文,以供广大作者免费阅览,以期待各位作者在短时间内掌握每种期刊征稿要求、审稿范围,在日常繁重的工作中短时间开心、放心快速投稿、在适合的时间拿到刊物,评上职称,不为挤不上评职称的末班车而烦恼。
本站主要整合如下评职称,发表论文:
教育论文发表
经济论文发表
科技论文发表
医学论文发表
计算机论文发表
文学论文发表
农业论文发表
学报论文发表
其它论文发表等,另期待更多的杂志编辑与本站联系文:
85782530(普刊发表)
82534308(核心发表)共同以正期刊界正刊之气,维护学术良好的氛围。
免责声明:本网所提供的信息资源如有侵权、违规,请及时告知!
论文网版权所有, 本站提供论文发表 论文投稿 发表论文 发表文章
文章只代表作者观点,并不意味着本站认同,部分作品系转载,版权归原作者或相应的机构;若某篇作品侵犯您的权利,请来信告知:lunww@126.com
中国论文网全权所属国际域名:www.lunww.com 中文域名:论文发表 技术支持:论文发表 国家双软认定单位 法律顾问:全民安律师事务所
期刊合作加盟咨询:5715378(加盟、投诉、建议) 论文发表咨询电话:18262951856 论文发表投稿邮箱:lunww@126.com
Powered by 论文发表 © 2010-2020

苏ICP备19023845号-4