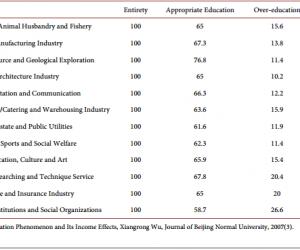
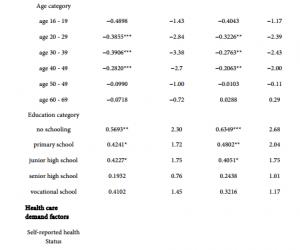
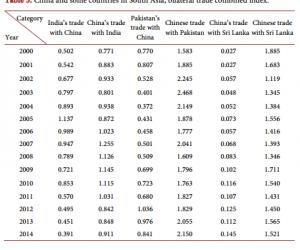
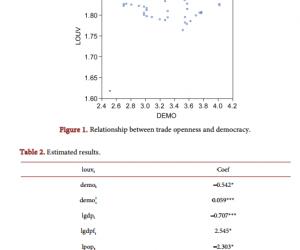
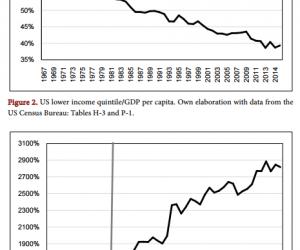
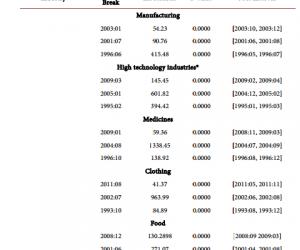
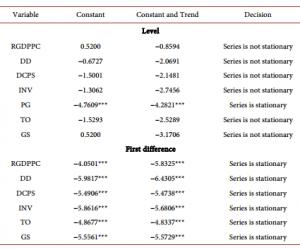
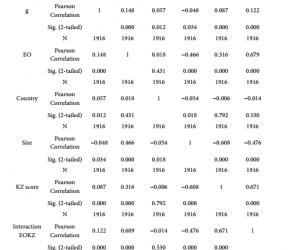
罗 丹 新疆农业职业技术学院新疆昌吉 831100
【文章摘要】
随着SVM 分类算法的不断完善和优化,其在人工智能及机器学习领域得到了广泛应用,并且也深入到了实际应用中。支持向量机早期仅用于监督学习,这些年随着半监督学习的迅速发展,支持向量机在半监督学习中也起到了很重要的作用。在如何划分低维空间向量集是一个普遍存在的难题,为了解决这个问题,我们需要找到一个合适的核函数,这样就可以能够有一个较好的存在于高维空间的分类函数。在支持向量机的理论中,每一个核函数都会产生一个不一样的算法,而这种算法的基础则是统计学理论。
【关键词】
人工智能;SVM 算法;分类器
随着人工智能及机器学习的飞速发展,数据在网络传播中的应用日益增多, SVM 分类算法在人工智能及机器学习领域得到了广泛的应用。支持向量机早期仅用于监督学习,这些年随着半监督学习的迅速发展,支持向量机在半监督学习中也起到了很重要的作用,并受到了广泛的亲睐。SVM 算法不仅在理论上有了很好的应用,在实际应用领域也得到了极大的推广和应用。核函数是支持向量机的很函数,这也是其受到亲睐的主要原因。在如何划分低维空间向量集是一个普遍存在的难题,通常为了解决这个问题,我们会把低维空间的向量集映射到高维度的空间中,但是在这个过程中会大大增加机器计算的时间复杂度,而解决这个瓶颈问题的方法就是选择合适的核函数,换言之,当我们找到一个合适的核函数,我们就能够有一个较好的存在于高维空间的分类函数。在支持向量机的理论中,每一个核函数都会产生一个不一样的算法,而这种算法的基础则是统计学理论。
支持向量机是基于线性划分的。但是可以想象,并非所有数据都可以线性划分。通常情况下,我们需要用一个曲线来划分存在于二维空间中的两个类别的点,以此来作为它的边界,而我们把低维度的点映射至高维空间,让其能够实现线性可分,映射后的我们通过线性划分作为依据来推断这个分类的边缘。在我们之前的数据空间中,它们都被视为非线性可划分的,在映射后的高维度空间中,我们视其为线性可划分的。但是在学习探索的郭晨各种我们主要需要思考的为题是其如何找到最优解,也就是我们所说的最优化问题,而非怎么去定义一个算法来实现性低维度到高维度的的映射问题。
在讨论SVM 分类的问题上,我也还要考虑其时间复杂度,通常我们所说的训练过程中的复杂度是指二次规划,在考虑其复杂度的时候通常我们要考虑两个问题,一个是解析解,一个是数值解,解析解相对来说比较的准确,它也属于我们理论上所能得到的解,我们用表达式来表达,换句话说,当一个问题只要是有解的,那么我们就可以说它一定是存在解析解的。但是这里我们需要强调虽然我们所解析解一定存在,但是能在有限或者相对有限的时间内解出这个解,或者一定能够解出解,这就是另一个问题了。我们在讨论SVM 的问题上考虑到时间复杂度最不理想情况是O(NSV3), 我们将支持向量的数量用NSV 表示,目前并没有一个特定的比例来规定训练集和支持向量的数量,但是我们一般情况下视支持向量的数量与训练集样本的大小是有关联的。因此我们可以了解在一对一的方法中,虽然训练两类分类器的数量很多,可是我们考虑总的花费时间要比一个和剩下的方法相对要上,这是因为其他的方法都把全部的训练样本都考虑进去,这样花费的时间就比较多,速度就会下降。
SVM 通过特征变换,将原来空间中的线性问题转化成为在新的空间中的线性的问题。在求解的过程中,所用到的分类器:
f(x)=sgn(w·x+b)=sgn( Σ αi·yi(xi·x) +b) ;
我们将x 特征进行一个非线性的变换将其记z=Φ(x), 那么就会产生一个新的支持向量机的决策函数在新的特征空间里:
f(x)=sgn(wΦ·z+b)=sgn( Σ αi·yi(Φ032
实验研究
Experimental Research
电子制作
(xi)·Φ(x))+b) ;
在新的空间域旧的空间的转变的过程中,所用到的K 就是我们所说的核函数:
K(xi,x)=(Φ(xi),Φ(x));
作为新的SVM 判别函数,用于新的空间中:
f(x)=sgn(wΦ·z+b)=sgn( Σ αi·y·K(xi, x)+b) ;
其中,系数ɑ 是下列优化问题的解:
Max Q(ɑ)= Σ ɑi-1/2·Σ ɑiɑjyiyjK (xi,xj);
S.t. Σ yiɑi=0;
最后我们就可以得到一个原来空间的用来分类的判别函数。
常用的核函数有:
1)多项式核函数: K(x,x’)=((x,x’) +1)q;
2)径向基核函数:K(x,x’)=exp(- ||x-x’||2/σ2)
3 ) S i g m o i d 函数:K( x , x ’) =tanh(v(x·x’)+c);
通过实验我们可以得到结果:使用model = svmtrain(label,data) 函数,有两类样本。data 是一个4x2 矩阵,表示有4 个样本, 每个样本有2 个属性。 则label 为4x1,可以用1,-1 来表示每个样本是属于哪一类。 (label 为分类,data 为矩阵。) 调用svmtrain 建立分类模型。 通过以下表达式可以对SVM 进行参数的设置。
1) -s svm 类型:SVM 设置类型( 默认为0) ;0 为 C-SVC ;1 为v-SVC ;2 为one class SVM ;3 为 e -SVR ;4 为v-SVR ;
2) -t 核函数类型:核函数设置类型( 默认为2) ;0 为 线性:u'v ;1 为 多项式:(r*u'v + coef0)^degree ;2 为 RBF 函数: exp(-r|u-v|^2) ;3 为sigmoid :tanh(r*u'v + coef0) ;
3) -g r(gama) :核函数中的gamma 函数设置( 针对多项式/rbf/sigmoid 核函数)
4)-c cost :设置C-SVC,e -SVR 和v-SVR 的参数( 损失函数)( 默认为1)
针对新样本,我们能够使用model 进行分类预测,利用高斯核函数及多项式核函数试验后结果如下图:
在支持向量机的实验中,我们可以看出机器计算的花费是由空间的高维度所决定,也就是说和核空间的维度没有关系,但是支持向量机的关键是如何选择合适的核函数、代价函数的平滑参数以及核参数,如果能选择好这些,那么久能够大大降低分类器的误差,所以说很函数的选择是支持向量机的关键。支持向量模型的求解, 从上述各种支持向量机的对偶问题表示可以看出,它们都是约束优化问题。即在一定的约束下,求解最优(极小)。 约束优化问题一般都转换为无约束优化问题进行求解。光滑无约束问题的求解方法一般有梯度下降法、牛顿法等。非光滑无约束问题可以转换为近似的光滑无约束问题。
【参考文献】
[1] 李瑜. 郑敏娟. 程国建.LI Yu.ZHENG Min-juan.CHENG Guo-jian 基于支持向量数据描述的分类方法研究[ 期刊论文]- 计算机工程2009,35(1) [2] 黄传波. 向丽. 金忠.HUANG Chuan-bo.XIANG Li.JIN Zhong 基于局部自适应逼近的半监督反馈算法[ 期刊论文]- 计算机科学2010,37(7) [3] 张健沛. 赵莹. 杨静.ZHANG Jian-pei.ZHAO Ying.YANG Jing 最小二乘支持向量机的半监督学习算法[ 期刊论文]- 哈尔滨工程大学学报2008,29(10)
[4]ZHOU Zhi-hua;WU Jian-xin;TANG Wei Ensembing neural networks:many could be better than all [ 外文期刊 2002(1-2)








论文发表 是一个专门从事期刊推广、论文发表、论文发表辅导的机构。融合收集数百家期刊杂志社征稿评职称,发表论文,以供广大作者免费阅览,以期待各位作者在短时间内掌握每种期刊征稿要求、审稿范围,在日常繁重的工作中短时间开心、放心快速投稿、在适合的时间拿到刊物,评上职称,不为挤不上评职称的末班车而烦恼。
本站主要整合如下评职称,发表论文:
教育论文发表
经济论文发表
科技论文发表
医学论文发表
计算机论文发表
文学论文发表
农业论文发表
学报论文发表
其它论文发表等,另期待更多的杂志编辑与本站联系文:
85782530(普刊发表)
82534308(核心发表)共同以正期刊界正刊之气,维护学术良好的氛围。
免责声明:本网所提供的信息资源如有侵权、违规,请及时告知!
论文网版权所有, 本站提供论文发表 论文投稿 发表论文 发表文章
文章只代表作者观点,并不意味着本站认同,部分作品系转载,版权归原作者或相应的机构;若某篇作品侵犯您的权利,请来信告知:lunww@126.com
中国论文网全权所属国际域名:www.lunww.com 中文域名:论文发表 技术支持:论文发表 国家双软认定单位 法律顾问:全民安律师事务所
期刊合作加盟咨询:5715378(加盟、投诉、建议) 论文发表咨询电话:18262951856 论文发表投稿邮箱:lunww@126.com
Powered by 论文发表 © 2010-2020

苏ICP备19023845号-4