【摘 要】系统突破单进程单机爬虫的瓶颈,设计了基于Redis分布式多爬虫共享队列的主题爬虫。采用Python开发的Scrapy框架来开发,Pycharm作为开发工具,使用Xpath技术对下载的网页进行数据的提取解析,运用Redis非关系型数据库做分布式,利用MongoDB非关系型数据库做数据存储,Scrapy-Redis组件作为辅助设计,并完成了能爬取网站上所有城市新房二手房数据的分布式爬虫系统。
【关键词】Python;Scrapy;Redis;MongoDB;分布式爬虫【引?言】各地城市持续的房屋交易需求,使得互联网上存在着海量房源数据,帮助用户获得具体的房屋信息就显得意义非凡。网络爬虫通俗理解成是一个模仿人类访问网站行为的程序或者脚本。该脚本能够自动地去请求网页、并把数据抓取回来,之后利用一定的规则去提取有价值的数据。基于Scrapy与Redis的分布式爬虫获取全国新房二手房信息,可以运行程序快速获取信息,包含地址、价位、户型、联系电话等,使得用户在信息爆炸的时代通过自己的手段获取到自己想要的数据,而非向他人寻求帮助或者买数据。
一、需求描述
(1)收集URL地址,比如说:房天下、好找房、贝壳找房等等,本文选取房天下网站,该网站数据量比较大,适合使用分布式爬虫去爬取;网站的数据非常有价值并且比较全的。
(2)分析网站。把网站熟悉透彻了才能在爬取数据的时候避免很多的问题。
(3)爬取数据。找到所需信息的位置,爬就完事了。
(4)提取数据。爬取到的数据很多都是混乱的,并且携带着其它数据,俗称脏数据,需要开发者根据需求取舍。
(5)保存数据。保存的方式也根据开发者的需求来确定,Redis、Mysql、MongoDB、json、excel等都可以。
(6)改造爬虫。在单机爬虫的基础上进行改造开发,最终转换为分布式爬虫。修改配置以及添加Scrapy-Redis组件即可。
(7)保存数据改。在这之前就保存数据的作用是查看所提取的数据是否正确,在此基础之上进行稍微的调整就行了。
(8)整个爬虫编写完成,开始测试各个模块。
二、设计
本爬虫属于分布式爬虫。首先实现逻辑这块,构建好爬虫的整套流程,爬虫这项技术的目标性很高,比如,需要怎样的数据、在何处获取、最终以什么样的形式呈现出来等,在此处目标选取为房价这块比较实用的数据。然后便是生产工具。项目开始时,首先要搭建开发环境,采用Python作为编程语言,使用Scrapy框架实现单机爬虫,其中,利用Xpath技术对下载的网页进行数据的解析提取,运用Redis作为非关系型数据库,由于Redis的特性,它在其中也担任着分布式服务器的功能,各台机器由Redis相连接,而爬虫与Redis之间则采用Scrapy-Redis组件相连接,最后使用MongoDB非关系型数据库做数据存储。
三、实现
网站分析是爬取数据的前提条件。首先,目标一定要明确。取房天下网站作为爬取目标,从房天下的首页“https://www.fang.com”着手起。要爬取的是整个搜房网的新房以及二手房的数据。从首页摸索可得出,显然左上角的“全国”字眼,这里“更多城市”,点击进去便是目标地点列表。
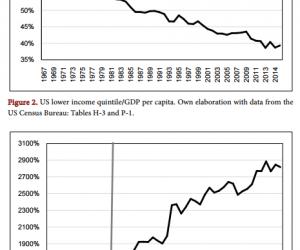
如下图所示:
图1城市列表图
该处便列出了全国各地总共658个城市的链接,多次选取不同城市的链接进行查看,发现各城市在该房天下网站下的子域名是“某个城市的拼音或者拼音的首字母.fang.
com”,例如安庆便是“anqing.fang.com”。接下来的操作步骤:
1.获取所有城市的URL链接。
2.让爬虫去访问这些城市的URL链接。
(1)在此基础上找到对应城市的新房的URL链接并访问。
(2)在此基础上找到对应城市的二手房的URL链接并访问。
本次爬虫的设计显得些许繁琐,需要访问各城市的URL链接,新房和二手房,频繁地浪费掉很多的网络资源,增添对方服务器的负担,可能也会使得自己被反爬虫。可调整操作步骤如下:
1.获取所有城市的URL链接。
可在此处获取:“h t t p s://w w w.f a n g.c o m/SoufunFamily.htm”
2.获取所有城市的新房的URL链接。
“某个城市的拼音或者拼音的首字母.newhouse.fang.
com/house/s/”例:上海:“https://sh.fang.com/”
上海新房:“https://sh.newhouse.fang.com/house/s/”
3. 获取所有城市的二手房的URL链接。
“某个城市的拼音或者拼音的首字母.esf.fang.com”
例:安庆:“https://anqing.fang.com/”
安庆二手房:“https://anqing.esf.fang.com”
上述操作把房天下网站下面所有城市的新房以及二手房的URL链接全部都给获取到,以便提取这些网页里面的数据。房天下关于这个URL链接的分析就完成了。
根据上一步的分析,遵循操作步骤做下去,因此,首先是对URL链接指向的页面进行详细分析,获取到所有城市的URL链接。使用Chrome浏览器的开发者工具(快捷键F12)来进行页面以及抓包分析。
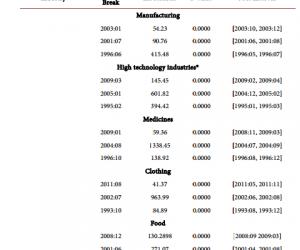
如下图所示:
图2城市列表页面分析图
目标数据都在这个“class”为“outCont”的“div”
标签中,而“div”标签中的每一个“tr”标签则代表其中每一行的数据,继续细分,每一个“tr”标签里含有三个“td”标签:通过开发者模式分析可知,第一个“td”标签里含有一个“class”属性,而其它两个都没有,且该“td”标签里没有包含我所需要的数据;第二个“td”标签是用来记录当前的城市是属于哪个省份的,这是目标数据中的一项,然而有些该标签是空白字符,这是由于页面排版的问题,大多数省份的城市数量太多,不能用一行来表示,于是就分成了几行,而这些城市都属于同一个省份,于是就只在其第一行标记出省份信息,后面的就为空白字符;第 三个“td”标签是用来存放城市数据的,包括城市的名字以及该城市的URL链接,其在该标签下的“a”标签中。该页面还有个细节,其“div”标签的最后还包括了一些其它的数据,比如,除中国以外的其它国家的信息,该类信息在我的需求中被称为“脏数据”,即不需要的数据,因此,后续需要设计出合理的逻辑去让爬虫剔除掉这些脏数据。
至此,该页面的解析已完毕。由该页面获取到的各城市的URL链接,通过上一步分析可知,经过些许的增删改操作就可以转换为对应城市的新房以及二手房的URL链接。下一步解析这些新房以及二手房里边的数据。
根据实用性以及该网站提供的数据来看,可从小区的名字、户型、建筑面积、小区所在行政区、小区具体位置、小区对应的价格、联系电话、目前是否在售以及在城市列表页就获取到的省份以及城市信息。房源数据都在“class”
为“nhouse_list”的“div”标签里(顺带说一句,之前以及往后的XML文档节点都是通过Xpath语法提取的,并且路径都为提取数据的最短路径。),通过观察此“div”标签可知,其里边的每一个“li”标签都存放着每一个小区的具体数据,包含每一个上述所需解析的数据。这样一分析来,过程就变得简单多了,现在只需利用好Xpath的语法,一个一个地将数据提取出来就行了。使用Chrome浏览器的开发者工具对翻页部分进行解析。
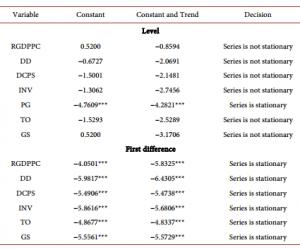
如下图所示:
图3广州新房翻页操作分析图
至此,与爬取新房数据相关的操作就完毕,而二手房的页面与新房的页面大同小异,故可以参照新房的相关操作来操作二手房数据。
小结
本文通过采用Scrapy框架,Pycharm作为开发工具,Red is非关系型数据库做分布式,MongoDB非关系型数据库做数据存储,Scrapy-Redis组件作为辅助设计来进行本套分布式爬虫的开发。系统未设置任何的管理与权限,封装的代码全部开源,目的皆在于让用户理解本设计如何做到的,加以学习并开发出更高级的爬虫,理解如何去反反爬虫,单从本次搜房网分布式爬虫的代码来讲,这个代码都是非常有价值的。
参考文献:
[1]张若愚 Python 科学计算 [M].北京:清华大学出版社.2012[2]樊宇豪. 基于Scrapy的分布式网络爬虫系统设计与实现[D].电子科技大学.2018[3]李小正,成功,赵全军. 分布式爬虫系统的设计与实现[J]. 中国科技信息.2014[4]成功,李小正,赵全军. 一种网络爬虫系统中URL去重方法的研究[J].中国新技术新产品.2014[5]明日科技.数据结构与算法.清华大学出版社[M].2015年6月作者简介;孙士兵(1977-),男,硕士,副教授,研究方向:数据挖掘,大数据及应用。