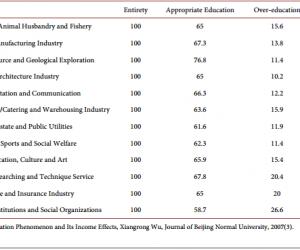
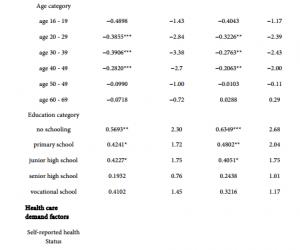
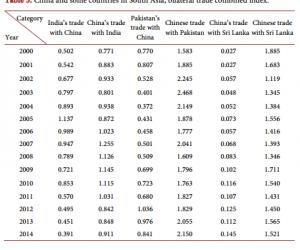
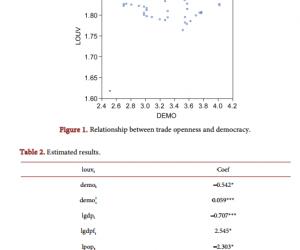
中医采用“望、闻、问、切”的诊断方法,并予以辨证施治,对慢性胃炎有很好的疗效。但是随着时间的流逝,一些宝贵的资源并没有被保存下来,老中医的经验是需要后人在实践的基础上不断领悟与总结方能表达的。需要从大量的临床资料中提炼出有价值、有共性的信息来帮助判断,从而达到辨证施治的目的。因而,笔者利用数据挖掘方法中的关联规则和决策树方法,以名老中医的胃炎病历信息为对象,对“症状”、“辨证”之间的潜在关系,以及根据“症状”如何判断是否能得到某一“辨证”做一初探。
基于以上目的,笔者利用现有的中医胃炎病历作为样本数据,采用关联规则的方法建立实验模型,并给出实验分析的结果。在此基础上采用决策树方法,构建一棵判断是否为辨证“中虚气滞”的决策树。
1 基于关联规则方法的中医胃炎分析
关联规则是数据挖掘领域中最为常用和成熟的方法之一。关联规则的挖掘问题就是在给定的事务数据库中,找出满足最小支持度(minsup)和最小置信度(minconf)的关联规则。关联规则有如下优点:可以产生清晰有用的结果;支持间接数据挖掘;可以处理变长的数据;计算的消耗量是可以预见[1]。经典的关联规则挖掘算法[2]有:Apriori算法[3]、抽样算法、DIC算法。
1.1 Apriori算法简介
Apriori算法先根据最小支持度,计算所有的1-项集(k-项集是含有k个项的项集),记为C1。找出所有满足支持度条件的1-项集,记为L1。然后根据L1确定候选2-项集的集合,记为C2。从C2找出所有满足支持度条件的2-项集,记为L2。依此类推,直到不再有候选项集。 医学职称论文发表
1.2 基于辨证“中虚气滞”关联规则的实验设计
我们首先根据“疾病标准表”、“中医临床诊疗术语”和南京中医药大学提供的“中药材表”,对病历中出现的症状、辨证与处方进行规范化,将词义相同或相近的整理归类,统一、减少或简化其称谓,消除别名。比如,面色中既有“面黄少华”又有“面色萎黄”,将其统一纠正为“面色萎黄”。然而,用文字描述的数据不利于计算机接收和处理,用数字来表达可以大大简化工作的复杂度。我们采用数值化的方法来体现某一症状的有无,将症状看成是布尔变量。
我们从中医胃炎病历中筛选出辨证为“中虚气滞”的病历,利用关联规则的Apriori算法来探求症状与此辨证之间的关系。我们根据中医胃炎病历中所涉及到的症状、辨证、处方等数据,在ACCESS中构建数据库及相应的表。其中sample表(见表1)中存放的是样本数据,即中医病历中辨证为“中虚气滞”的病历。这里的每条记录代表辨证为“中虚气滞”的一条病历,分别由不同的症状构成。Symptom表(见表2)中存放的是中医胃炎病历中所涉及到的所有症状名称及其相应的编号。 表1 sample表(略)表2 symptom 表(略)
利用VC6.0作为开发平台,从运行界面上输入支持度和辨证“中虚气滞”所涉及到的症状数目,根据Apriori算法运行程序,最后得到辨证“中虚气滞”与症状之间的关系。
1.3 基于辨证“中虚气滞”关联规则的实验结果分析
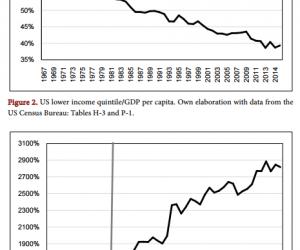
关联规则有两个评价标准:支持度和置信度。置信度描述的是包含A和B的事务数与包含A的事务数的百分比。由此可见,置信度度量规则的强度是我们关注的重点。以男性病历为例,最后得到最大频繁项集是{胃脘痞胀,舌苔薄(白),吞酸或泛酸,舌质红},以下列举部分结论以供分析。
置信度:舌苔薄(白)=>中虚气滞(50%);舌质红=>中虚气滞(66%);胃脘痞胀∧舌苔薄(白)∧吞酸或泛酸∧舌质红=>中虚气滞(100%)。
置信度表明:只有舌苔薄(白)这一症状时,辨证为“中虚气滞”的概率是50%;只有舌质红这一症状时,辨证为“中虚气滞”的概率是66%;症状胃脘痞胀,舌苔薄(白),吞酸或泛酸,舌质红同时出现的前提下,辨证为“中虚气滞”的概率是100%。
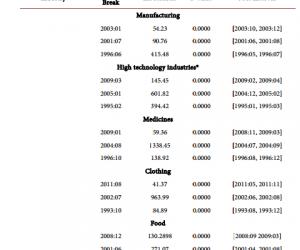
由女性病历分析,得到症状的两个最大频繁项集是{舌苔薄(白),脉细弦,口干(欲饮),胃脘隐痛}和{舌苔薄(白),脉细弦,胃脘嘈杂,舌质淡},以下列举部分结论以供分析。
置信度:舌苔薄(白)=>中虚气滞(22.2%);脉细弦=>中虚气滞(25%);胃脘隐痛=>中虚气滞(40%);口干(欲饮)=>中虚气滞(66.7%);舌苔薄(白)∧脉细弦=>中虚气滞(25%);胃脘隐痛∧舌苔薄(白)=>中虚气滞(50%);脉细弦∧胃脘隐痛=>中虚气滞(66.7%);脉细弦∧胃脘隐痛∧舌苔薄(白)=>中虚气滞(66.7%);舌苔薄(白)∧脉细∧口干(欲饮)∧胃脘隐痛=>中虚气滞(100%);舌苔薄(白)∧脉细∧舌质淡∧胃脘嘈杂=>中虚气滞(100%)。
由实验结果可知,在单个症状出现的情况下,症状口干欲饮对于辨证“中虚气滞”的影响最大;当两个症状同时出现的情况下,症状脉细弦和胃脘隐痛能导致是辨证“中虚气滞”的可能性为66.7%,是其他几种两个症状同时出现的可能性中最大的。当同时出现舌苔薄(白)、脉细、口干(欲饮)、胃脘隐痛和舌苔薄(白)、脉细、舌质淡、胃脘嘈杂这2组症状时,都可判断辨证是“中虚气滞”。 医学职称论文发表
由此可见,应用关联规则方法对中医胃炎病历进行分析确实能在一定程度上揭示辨证与症状对应的规律,从中提取有用知识,为临床及实验研究提供进一步探索的线索和目标。
2 基于决策树方法的中医胃炎分析
决策树算法是目前应用最广泛的归纳推理算法之一[4],是一种逼近离散值函数的方法,通常用来形成分类器和预测模型[2]。决策树分类方法采用自顶向下的递归方式。从决策树的根到叶结点的一条路径就对应这一条合取规则,整棵决策树就对应着一组析取表达式规则。
2.1 ID3算法简介
ID3算法先确定每一个实例属性单独分类训练样例的能力,将分类能力最好的属性选做树的根结点。然后为根结点属性的每个可能值产生一个分支,并把训练样例排列到适当的分支之下。重复整个过程,用每个分支结点关联的训练样例来选取在该点被测试的最佳属性。由此可见,ID3算法总是选择分类能力最好的属性作为当前结点的测试属性。ID3算法选用信息增益作为选择最佳属性的度量标准。为了精确定义信息增益,先定义信息论中广泛使用的一个度量标准——熵。
Entropy(S)=
其中:S为某个目标概念的正反样例的样例集,P+是在S中的正例的比例,P-是在S中反例的比例。
一般情况,如果目标属性具有C个不同的值,那么S相对于C个状态的分类的熵定义为:Entropy(S)=
。
一个属性A相对样例集合S的信息增益Gain(S,A)被定义为:Gain(S,A)=Entropy(S)-
。
其中:Values(A)是属性A的所有可能值的集合,SV是S中属性A的值为V的子集。
ID3算法就是选择信息增益最大的候选属性作为结点,然后向下创建分支。
2.2 辨证“中虚气滞”决策树的实验设计
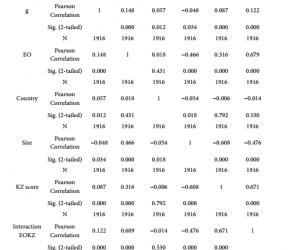
我们希望能利用现有的中医胃炎病历来构建一棵能够判断症状与辨证“中虚气滞”关系的决策树。我们根据关联规则分析中得到的结论,从94条中医胃炎病历中涉及到的77种症状中剔除与辨证“中虚气滞”完全没有关系的属性及其所属的病历,从而缩减症状数目即候选属性,避免生成的决策树过于庞大、冗余。我们构造了目标属性是“中虚气滞”的训练样例(见表3)。辨证“中虚气滞”作为目标属性,它有Yes和No两个值,其中Yes代表由该条病历的症状能得出辨证是“中虚气滞”,反之,No代表不是这一辨证。我们将通过其他属性(这里指病历中的症状)来预测这个目标属性的值。其中,胃脘嘈杂、灼热、舌苔薄(白)等是从94条病历涉及的77种症状中筛选出来的18条对于辨证“中虚气滞”有较大贡献率的属性,作为候选属性。训练样例中每行数字代表一条中医胃炎病历。其中1代表该条病历中含有这一症状,反之,0则为不含有这一症状。
2.3 辨证“中虚气滞”决策树的实验结果分析
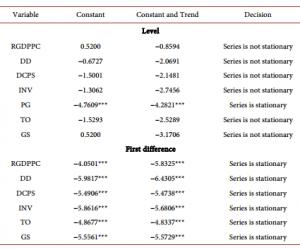
根据表3的训练样例运用ID3算法构建的决策树见图1。决策树建立的规则是指导决策树分类的重要依据,规则以“IF…THEN”语句形式陈述,最末一个IF对应的变量位于决策树的根节点。根据图1所示的决策树,我们可以得到关于辨证“中虚气滞”的很多分类结论。比如:如果经过“望、闻、问、切”,某人舌质红、易嗳气、脉细弦,但是不便秘,那他很有可能是“中虚气滞”;如果某人舌质红、不便秘、易嗳气、脉细弦,但是并不吞酸、泛酸,则他很可能就不是“中虚气滞”,这为临床诊断提供了帮助。未知中医证型的病例就是按照规则归属到已知的证型中,从而完成证型的预测。因而,当给出新的病历后,我们就可以根据这棵决策树来判断某人是不是“中虚气滞”。表3 目标属性“中虚气滞”的训练样例(略) 医学职称论文发表
决策树能得出一些对于目标属性有重要意义的症状。如:舌苔和舌质颜色、苔质的情况,大便便次异常的情况,嗳气,胃脘疼痛的性质等,这些对临床诊断都能起指导作用。
3 结语
决策树在本次研究慢性胃炎中医辨证分型的问题中表现出了重要的优势,建立了较为令人满意的预测模型。当然,还有需要进一步完善的地方,如:由于病历中所涉及的症状数目较多,也就是候选属性较多,构建成的决策树分支较为庞大,因而事先做了数据预处理。在以后的工作中,我们可以采用对生成的决策树进行剪枝的方法,剔除掉一些不重要的候选属性,避免过度拟合,使最后的结果更具有客观性。随着数据挖掘技术的推广,关联规则和决策树算法的不断改进,其在中医学上的应用将不仅仅局限于某个领域,将为中医诊治疾病规律和用药规律的探索做出贡献。








论文发表 是一个专门从事期刊推广、论文发表、论文发表辅导的机构。融合收集数百家期刊杂志社征稿评职称,发表论文,以供广大作者免费阅览,以期待各位作者在短时间内掌握每种期刊征稿要求、审稿范围,在日常繁重的工作中短时间开心、放心快速投稿、在适合的时间拿到刊物,评上职称,不为挤不上评职称的末班车而烦恼。
本站主要整合如下评职称,发表论文:
教育论文发表
经济论文发表
科技论文发表
医学论文发表
计算机论文发表
文学论文发表
农业论文发表
学报论文发表
其它论文发表等,另期待更多的杂志编辑与本站联系文:
85782530(普刊发表)
82534308(核心发表)共同以正期刊界正刊之气,维护学术良好的氛围。
免责声明:本网所提供的信息资源如有侵权、违规,请及时告知!
论文网版权所有, 本站提供论文发表 论文投稿 发表论文 发表文章
文章只代表作者观点,并不意味着本站认同,部分作品系转载,版权归原作者或相应的机构;若某篇作品侵犯您的权利,请来信告知:lunww@126.com
中国论文网全权所属国际域名:www.lunww.com 中文域名:论文发表 技术支持:论文发表 国家双软认定单位 法律顾问:全民安律师事务所
期刊合作加盟咨询:5715378(加盟、投诉、建议) 论文发表咨询电话:18262951856 论文发表投稿邮箱:lunww@126.com
Powered by 论文发表 © 2010-2020

苏ICP备19023845号-4