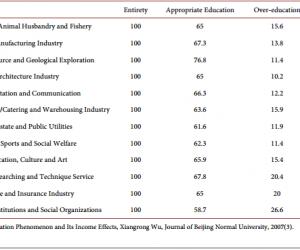
[摘 要]由于网站的结构设计,对特定用户而言信息获取的代价与所经过的浏览路径长度成正比,这些位于路径中间的不必要的文档就无疑增加了用户获取信息的代价。本文利用Web挖掘的方法和技术对用户所访问的页面序列进行挖掘,构建路径优化的模型,实现对当前站点排序方式的优化,从而最大限度地优化用户访问体验,提高当前站点信息获取的整体效率。
[关键词]站点路径优化;Web挖掘;访问序列
传统的Web网站以系统自身为中心,为了容纳大量的信息,以图结构组织网站,页面之间存在着比较复杂的层次关系。这些预先设计好的浏览路径(网站的结构)严格按照设计者编辑好的层次返回页面,因此,为了获取特定的信息,从同一页面出发的所有用户都不得不重复地经过很多与自己毫无关系的、不希望看到的中间链接页面,使得用户为了获取少量的信息付出较大的代价[1]。如果在确保网页内容的前提下,实现网站物理结构的调整和再组织,就可以避免混乱。站点路径优化实际上就是站点管理者优化其站点结构,它的出现就是为了提高用户的访问效率以及用户对站点的忠诚度。
1 站点个性化与路径优化
Web站点结构设计好坏的衡量标准之一是用户为获取所需信息所付出的平均代价,而这种代价则可以理解为所经过的超链数目和选择这些超链的困难程度的函数。用户的浏览路径优化就是在尽量不破坏Web系统原有结构,即不删除系统原有文档和超链的前提下,通过增加新的超链或文档来减少用户获取信息所需付出的平均代价[2]。
所谓站点个性化实质上就是为站点用户提供个性化的站点访问体验。对于一般站点而言,站点管理者进行路径优化的直接目的就是提高用户点击行为的效用度,最终目的是提高用户满意度与忠诚度。站点路径的优化实际上就是优化站点结构,消除站点实际安排与用户期望之间差异的过程,它为站点个性化提供了一种思路,即用户一系列的浏览行为所遍及的页面序列就是用户针对目标页面的寻找过程,此时站点设计可以考虑调整网站的结构、在频繁访问路径处添加指向目标页面的链接,或者是将常见浏览路径加入缓存,如图1所示。
图1 网状结构中的路径优化
网站的频繁浏览路径体现了特定的用户在特定时期内的活动规律,是站点路径优化的依据。它包括两个方面的内容:首先是个体用户在其浏览历史区域中多次重复出现的浏览路径,另一方面即用户群体在一定时期中浏览历史区域内出现的浏览重复行为,即浏览模式。
个体用户的一条浏览路径对应于用户的一段信息探求过程。根据个体用户的重复浏览路径,就可以形成用户兴趣视图,并依据用户兴趣视图完成个性化推荐,为用户提供定制的访问体验。而用户群体在较长时期内稳定的行为模式则为网站结构的改进和路径的优化提供了参考依据。如果在一定时期内大多数用户都表现出访问路径的相似性,此时Web站点就要做相应的访问路径优化。
前者可以为用户提供“一对一”的具备自适应性的在线动态智能个性化服务,这种智能个性化服务可大大缩短用户在网络上的访问延迟,使得提供给用户的网络信息服务质量得到最大限度的提高。后者则通过离线修改实施改进,用以优化用户浏览体验,提高当前站点信息获取的整体效率,同时提高用户满意度和忠诚度。2 基于Web挖掘的路径优化模型
Web挖掘从数据挖掘发展而来,但Web挖掘与传统的数据挖掘相比有许多独特之处。首先,Web挖掘的对象是大量、不同和分散型的Web文件;其次,Web文件本身是半结构化或无结构的,因此Web挖掘所得到的模式可能是关于内容的,也可能是关于结构的;最后,有些数据挖掘技术并不适用于Web挖掘,即使可以用也需要建立在对Web文件进行预先处理的基础之上[3]。
2.1 访问序列挖掘实现过程的理论分析
为了跟踪用户以往浏览的网页,对网页访问数据进行挖掘,Web挖掘技术以Web日志为数据源。因为每当用户在点击链接向站点发出页面浏览请求时,该用户的IP地址、浏览日期和时间、浏览页面URL及引用页面等信息会被记录在Web日志中,用户浏览点击页面就按照时间顺序以页面URL序列的形式隐藏在Web日志中[4]。用户访问序列挖掘即通过对Web日志进行系统的分析和预处理,将用户以往的浏览序列从日志中提取及表示出来,并采用各种Web挖掘方法和算法从不同的角度获得各类用户可能的网页浏览顺序,探索总结出用户浏览网页的规则和模式。在获得用户浏览规律之后,通过模式分析识别用户需求的链接,确定用户浏览行为的目标就可以提高用户浏览的总体性能,帮助改进网页的设计和网站的链接结构,同时确定可以用于缓存的浏览网页信息[5]。
从服务器的角度分析,挖掘发现的是提供服务的网站的信息,挖掘结果可以帮助改善网站的设计。从用户的点击序列分析,可以发现一个(或者一组)用户的信息,可帮助实现网页的预存取和缓存[6]。
2.2 站点路径优化的模型构建
以Web日志为数据源进行的站点路径优化的挖掘模型,采用了数据挖掘及Web日志挖掘的相关技术和算法获取用户浏览规则与模式,为网络结构优化、站点重构提供参考及个性化服务推荐设计提供了依据。据此站点路径优化的模型可分为数据预处理和站点路径优化实现两个部分,站点路径优化部分可从两个方面来考虑[7]:一是通过对Web日志的挖掘,发现用户的期望位置。如果在期望位置的访问频率高于实际位置的访问频率,可考虑在期望位置和实际位置之间建立导航链接,从而实现对Web站点的优化。二是通过对Web日志的挖掘,发现用户访问页面的相关性,从而对密切联系的页面之间增加链接,方便用户使用。如图2所示。
图2 利用Web挖掘技术的路径优化模型
3 站点路径优化的实现
3.1 Web日志数据收集
Web服务系统是一个多层次的逻辑结构,包括客户端、代理服务器端、Web服务器端。本文挖掘的是本站点用户的频繁访问路径、用户聚类等,因此适合采用Web服务器端的用户访问模式挖掘[8]。Web服务器日志由三部分组成:访问日志、引用日志和代理日志,包括用户访问Web站点时,所访问的页面、时间、用户ID等信息。
3.2 站点数据预处理
Web站点及访问数据预处理部分主要包括站点结构数据预处理、内容数据预处理和Web日志数据预处理。其中,结构数据预处理的任务是描述站点的拓扑结构图、站点页面文件链接有向图,并明确站点各个页面文件链接的请求(Request)方法,如GET、POST、HEAD等。站点内容数据预处理包括将文本、图片、脚本和其他多媒体文件转变为用户对站点浏览模式记录信息的开发与利用有用的格式[9]。
用户访问序列挖掘的Web日志数据源预处理包括数据过滤、格式转换、用户识别、会话识别、路径补全和事务识别,预处理过程是保证后继挖掘质量的关键。
3.3 基于Web日志挖掘的路径优化实现
论文发表 在数据预处理之后,对所形成的用户会话文件,利用数据挖掘的一些有效算法(如关联规则、聚类、分类、序列模式等)来发现隐藏的模式规则。由于传统的手工决策规则系统方法、基于内容的过滤代理系统方法、协作过滤系统方法的种种不足,并且就分析和建立模型的技术而言站点路径挖掘和传统的数据挖掘差别并不是特别大,所以路径优化模式除了可以运用Web数据挖掘的很多方法和算法思想,也可以采用一般的统计方法和在线分析处理方法,如聚类分析方法、关联规则分析方法和序列模式分析方法等[10]。
站点路径优化可以分为两类:用户群访问模式挖掘的路径优化和个性化挖掘的路径优化。一般访问模式挖掘的路径优化通过分析在特定时间点的特定用户群的访问记录来了解用户的浏览模式和倾向,以改进站点的组织结构;而个性化挖掘的路径优化则倾向于分析个别用户的偏好,其目的是根据用户的访问模式,为其提供定制服务。
3.3.1个性化的浏览路径优化。Web站点的链接结构是Web设计者根据一定的策略建立起来的,可能与用户期望的链接结构之间存在一定的差距。如图3.1所示,目标页面X放在页面B1下,但是用户浏览路径是F→A2→B2,因此用户期望页面X的位置在A2或B2下。如果事先能了解用户的期望位置,从而在A2(或B2)和页面X之间建立导航链接,自然就方便了用户,提高了网站的访问效率[1]。
(1)发现用户期望位置。
设{P1,P2,...,Pn}为用户访问过的页面,Pn是一个目标页面,B=Ф;∥B为回溯点的集合;
图3 用户访问站点路径
For(i=2;i<=n-2;i++)
{if(Pi-1=Pi+1) or (no link from Pi to Pi+1) add Pi to B} ∥Pi是一个回溯点;
If (B not empty) add n,B,Pn-1> to table;
通过该算法,就可以找到用户的返回点,这个位置可能是期望位置,也可能是目标页面,但可以通过确定时间阈值来解决这个问题。当用户在返回点停留的时间较长,超过指定的阈值,则认为该页面是目标页面,否则可以认为该页面是期望位置。通常用户在浏览Web站点时,在第一期望位置找不到目标页面,就会在第二期望位置找,如果还找不到,会在第三期望位置找……,其中最受关心的是第一期望位置,而且是那些被第一期望且发生频率高于系统设计者指定值的所有页面。因此,寻找第一期望位置便成了我们关注的焦点[12]。
(2)目标位置和期望位置的判定。设Ei表示第一期望位置,算法如下:先以用户的ID为主关键字,时间为次关键字,对Web日志文件建立索引,扫描Web日志索引文件,对每一个用户ID,摘取出页面序列。
For (I=1;I<=1;I++)∥n为Web日志中的记录数
{统计E?i中所有页面支持数;
Sort page by support;
If support(P)>=SI ∥SI为Web设计者制定的阈值;
则P为被第一期望且发生频率高于系统设计者指定值的页面}
经过提取目标页面与期望位置之后,将形成如表1的目标页面与期望位置匹配集[13]。
(3)调整站点结构。根据该算法的挖掘结果,很多内容页面(目标页面)的实际位置与用户所期望的位置不一致,可以考虑依据这些目标页面的用户期望位置来调整目标页面的实际位置。第一期望位置、第二期望位置……这些页面从某种角度看是围绕同一主题展开的,访问了其中部分页面的用户往往也会访问其他页面,因此可以在这些页面之间设置推荐链接。
3.3.2 用户群访问模式的路径优化。对用户群访问模式的问题,采用挖掘频繁访问的最大序列的方法可以挖掘出更有普遍意义的模式,算法包括有Apriori算法,最大向前序列法,参考长度法和树形拓扑结构法等。它们先将日志中的用户浏览历史记录转换成一个浏览子序列集:最大向前序列法根据用户折返的特性形成若干浏览子序列;参考长度法根据用户在网页上停留的时间形成若干个浏览子序列;树形拓扑结构法则把整个日志当作浏览子序列。然后利用关联规则法对浏览子序列进行挖掘找出频繁访问路径。频繁浏览路径就是指按照一定顺序组成的网页序列集,用户依照此序列访问网站的频度很高。
根据频繁访问路径算法得到频繁访问路径FP,对应记录为X(fp,np),其中fp表示URL组成的序列,np表示浏览路径集合中FP出现的次数[14]。
for all X∈FP
for all Y∈FP and Y≠X
if X. fp∈Y. fp. sub then X.np=X.np-Y.np
∥ 检查X. fp是否为另一记录Y. fp的子序列
If X. np > n
∥ n为预先设定的次数阈值
set Suplnik( X . fp)
论文发表 ∥设计新的从X. fp起点指向终点的超链。
该方法可以用于重构Web站点的页面之间的链接关系,及重构Web站点的拓扑结构、发现相似的客户群体,开展个性化的信息服务和有针对性的电子商务活动,应用信息推拉技术构建智能化Web站点。
4 结 语
站点路径优化就是通过Web挖掘技术来收集和统计用户访问过的历史数据,挖掘当前用户频繁访问的页面序列,对个体用户获取其兴趣模型,以便在用户以后的访问过程中根据兴趣模型自动向用户推荐内容,指导用户的浏览行为,提高浏览信息效率。对群体用户获取其访问路径规则与模式,通过增加超链改进站点结构,将页面加入缓存提高访问速度,提高用户对站点访问的满意度[15]。访问规律的获取对算法提出了较高的要求,可以借鉴现有模式发现算法实现浏览结构的优化。